StudyRAG: AI teaching assistant for course materials
2025Course-materials Q&A app with inline citations. Built as a four-person class project, then rebuilt solo with an agentic backend and hybrid retrieval pipeline.
- LangChain
- LangGraph
- ChromaDB
- FastAPI
- AWS
- RAG
The problem
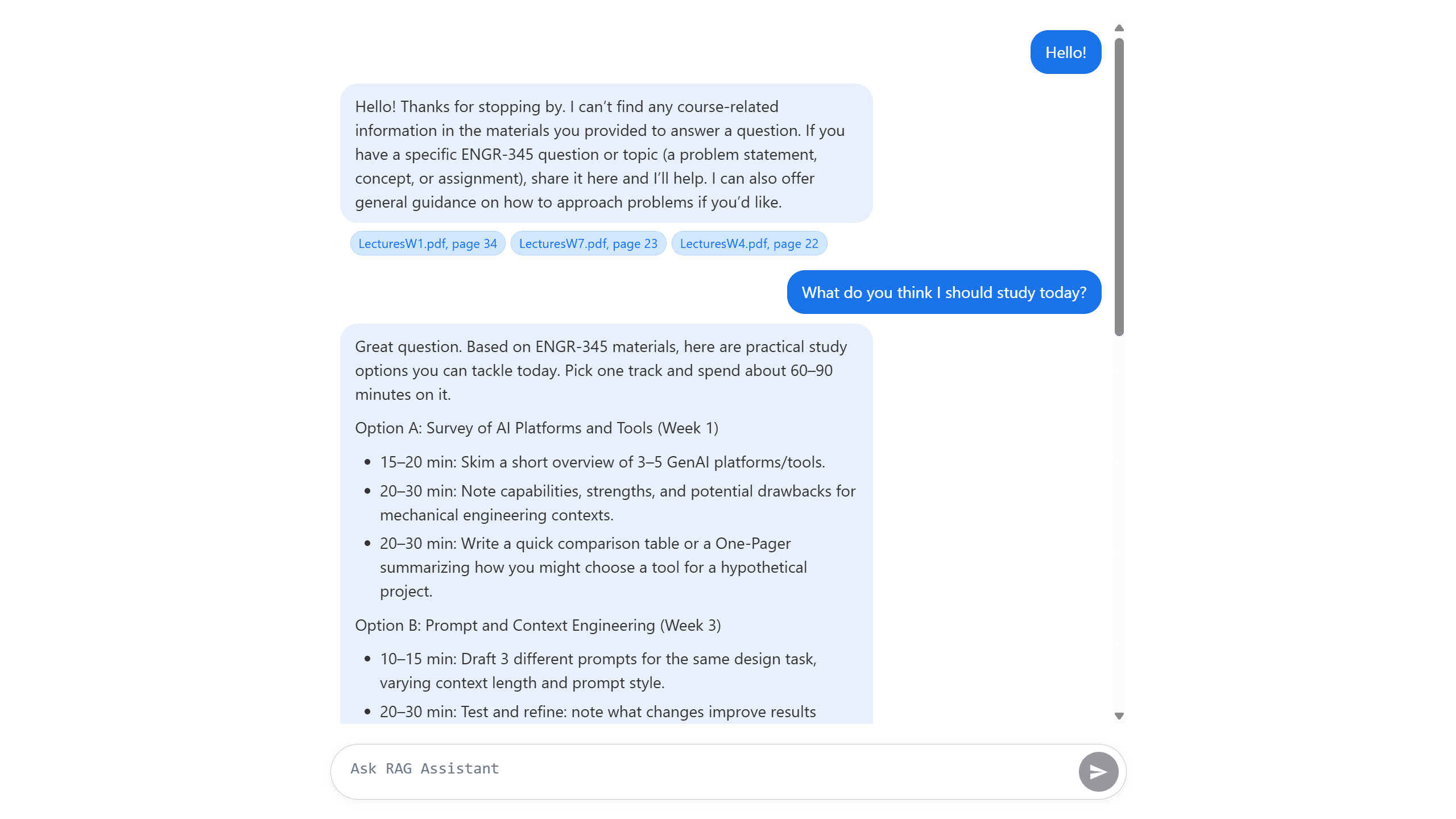
In a typical engineering course, the source-of-truth material is scattered across a syllabus, weekly lecture slides, assignment PDFs, and reference texts. Searching across them is keyword-only at best, and asking a general-purpose LLM gets you confident answers about the concept but no real link to this course's materials, where the policies, notation, and emphasis actually live.
StudyRAG closed that gap. Point it at a folder of course documents and you could ask things like:
- "What's the late submission policy?"
- "Where did we cover Mohr's circle?"
- "What's the difference between VAEs and GANs in the slides?"
Every answer came back with clickable citations to the exact source page, so you could verify the claim yourself.
v1: class project
The first version was a four-person team project for Effective Use of AI Tools for Scientists & Engineers (ENGR-345). The architecture was deliberately straightforward:
- Backend: Flask
- Vector store: FAISS, built offline by
ingest.py - Retrieval: semantic similarity over OpenAI
text-embedding-3-smallchunks, produced by LangChain'sSemanticChunker - Generation:
gpt-5-nanodriven by two prompts: a history-aware query reformulator and a strict context-grounded QA prompt - Citations: the backend extracted the source filename and page from each retrieved chunk and rendered them as clickable links to the original PDF
The single most useful design decision was the strict QA prompt:
You are an expert teaching assistant for the ENGR-345 course.
Your primary role is to answer questions based ONLY on the provided
course materials.
If the context does not contain the answer to the question, you MUST
state that you cannot find the answer in the provided documents.
That instruction alone eliminated most of the false-confidence answers we were seeing in early tests, and made the citation feature actually meaningful: if the model has to ground its answer in the retrieved chunks, the citations to those chunks become real evidence rather than decoration.
The v1 codebase is on GitHub: xanderscannell/RAG-AI.
v2: what I rebuilt afterward
After the class ended I kept working on it solo, mostly as an engineering exercise. Two limitations from v1 had started to bother me:
- Pure semantic retrieval missed exact-term queries. "What was the formula on slide 14?" or "what does ENGR-345 mean by thermal stress specifically?" These need keyword matching, not paraphrase matching, and semantic-only embeddings frequently surfaced conceptually adjacent but factually wrong chunks.
- It was hard-coded to a single course. Adding a second course meant rebuilding the whole vector store from scratch.
So I rewrote most of it.
Hybrid retrieval
The retrieval pipeline ran three stages:
- Semantic search over chunked embeddings, now in ChromaDB
- BM25 keyword search over the same chunks via
rank-bm25 - Cross-encoder rerank on the merged top-k using
cross-encoder/ms-marco-MiniLM-L-6-v2
The cross-encoder rerank was the single highest-leverage change. It only ran on a small candidate set (the top-k merged from semantic and BM25), so the added latency was small, but the relevance gain was sharp: concept questions still surfaced conceptual chunks, and exact-term questions stopped returning vaguely related lecture slides.
Agentic backend with course scoping
The chatbot moved from a flat LangChain chain to a LangGraph agent, with one CourseAgent instance per course. Each agent owned its own ChromaDB collection and document store, so adding a new course was just dropping PDFs in a directory and running ingest with a fresh course_id, with no code changes and no shared-index contamination across courses.
FastAPI and AWS
The backend moved from Flask to FastAPI for async request handling, better request/response typing, and automatic OpenAPI docs. I deployed it to AWS Elastic Beanstalk, which is where I lost a weekend to IAM permission issues before getting it up.
What I'd do differently
- Eval set first, retrieval strategy second. I built and compared three retrieval pipelines before I had a proper eval harness, which means I spent real time tuning chunk sizes and rerank thresholds on vibes. Next time I'd write 30–50
question / expected-answer / expected-source-pagetriples up front and gate any retrieval change on a rerun of that set. - Skip Elastic Beanstalk for projects this size. EB abstracts too much for a use case this specific. ECS / Fargate gets you essentially the same managed-Docker outcome with a much shorter list of mystery IAM permissions.
- Prompt-level guardrails complement retrieval, they don't replace it. The "answer ONLY from context" instruction worked reliably given good retrieval. With bad retrieval, the model just confidently cited the wrong chunks. Hybrid retrieval and reranking were what actually moved the factual-answer needle.
Stack
- Backend: FastAPI, LangChain, LangGraph, ChromaDB, OpenAI API
- Retrieval: semantic + BM25 + cross-encoder rerank
- Frontend: vanilla JS with Markdown rendering and DOMPurify sanitization
- Deployment: AWS Elastic Beanstalk